
Build only what you need to build, and do it fast
Với sự phát triển không ngừng của công nghệ, đâu đâu người ta cũng nhắc tới Cách mạng công nghiệp 4.0. Trong bối cảnh đó, Học máy (Machine Learning) đã trở thành một cái tên không còn xa lạ trong giới công nghiệp. Cùng với nhu cầu ngày càng nhiều của xã hội, một ngành mới được ra đời, Kĩ sư Học máy (Machine Learning Engineers).
Kĩ sư Học máy là người có cả kĩ năng về Học máy và Kĩ thuật phần mềm (Software Engineering). Một Kĩ sư Học máy có thể sử dụng các kĩ năng của mình để tìm ra những mô hình học máy có hiệu suất cao đem vào ứng dụng và cũng là người xử lý các vấn đề từ cơ sở hạ tầng phục vụ huấn luyện cho đến tạo ra mô hình áp dụng thực tế. Có kha khá nguồn tài liệu trên mạng để một Kỹ sư phần mềm hay bất cứ ai học về Học máy. Tuy nhiên, trong thực tế, một đội ngũ làm Học máy sẽ phải đối mặt với vấn đề: Làm sao để có thể quản lý các tiến trình của dự án như các dự án phần mềm truyền thống ? Sau đây là bài viết trả lời cho câu hỏi đó.
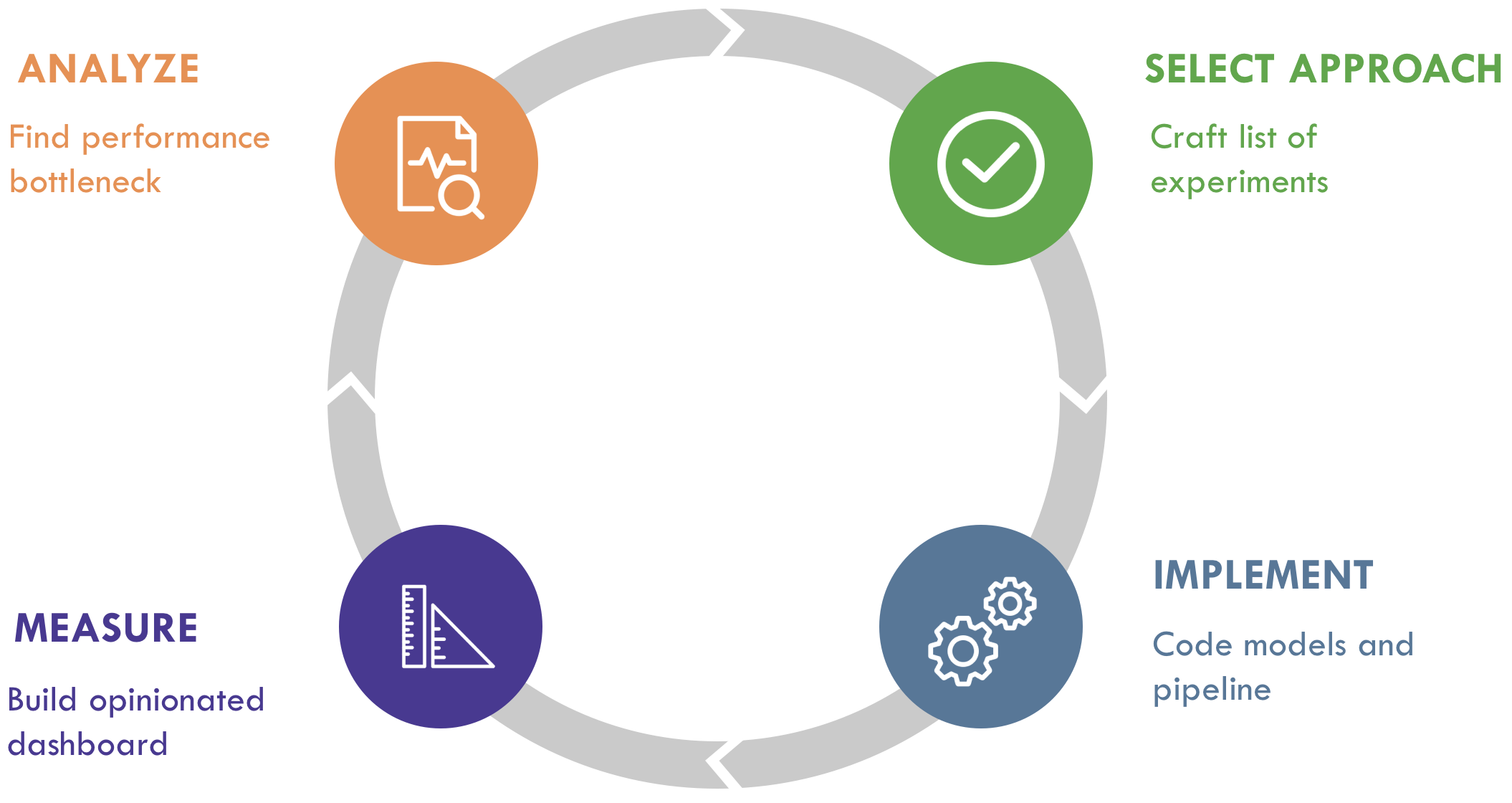
The ML Engineering Loop
Trong bài viết này, chúng mình sẽ cùng tìm hiểu về khái niệm “OODA Loop” của Học máy: ML Engineering Loop, với khái niệm này một Kỹ sư sẽ tuần tự theo các bước
-
Phân tích (Analyze)
-
Chọn phương pháp (Select an approach)
-
Thực thi (Implement)
-
Đo đạc (Measure)
để có thể tìm ra được mô hình học máy hiệu quả một cách nhanh chóng. Đối với mỗi giai đoạn sẽ có những lời khuyên mà tác giả nghĩ có thể hữu ích trong việc tối ưu toàn bộ quá trình.
Một đội ngũ ML thành công khi triển khai được mô hình có hiệu suất cao với những rằng buộc đã cho (ví dụ: đạt độ chính xác cao nhưng vẫn phải đảm bảo về bộ nhớ, thời gian chạy, etc). Hiệu suất (performance) được định nghĩa là đơn vị đo liên quan nhất tới thành công của sản phẩm cuối. Hiệu suất sẽ được dịch sang ngôn ngữ tương ứng của Học máy để quy về các độ đo. Trong ví dụ dưới đây, tác giả sẽ chọn “error rate” là đơn vị đo hiệu suất.
Khi mới bắt đầu, bạn nên định nghĩa ra tiêu chí như nào thì gọi là thành công. Dưới góc nhìn về sản phẩm, theo bạn, hiệu suất như thế nào thì bắt đầu gọi là hữu dụng? Ví dụ như hệ thống của bạn gợi ý ra 5 bài báo liên quan, ít nhất bao nhiêu trong số đó cần phải thực sự liên quan, và thế nào là liên quan ?
ML Engineering Loop sẽ giúp bạn định hình được quá trình phát triển, đơn giản hóa quá trình quyết định để có thể tập trung hơn vào bước tiếp theo. Khi đã quen dần với vòng lặp này, bạn sẽ có thể nhanh chóng luân phiên giữa phân tích và thực thi. Vòng lặp này còn hữu ích kể cả khi bạn đã là chuyên gia, bạn sẽ không bị ngợp hay mông lung khi mô hình không đáp ứng yêu cầu hay đột nhiên mục tiêu của nhóm thay đổi.
Bắt đầu nào
Để có thế “kích” vòng lặp, hãy bắt đầu từ một phiên bản đơn giản. Mục đích của việc “kích” này là để có 1 con số cho chúng ta đánh giá, làm cơ sở cho việc đánh giá sau này. Nó sẽ bao gồm các việc sau:
-
Chuẩn bị dữ liệu training, development và testing.
-
Áp dụng một mô hình đơn giản chạy được.
Ví dụ, có thể sử dụng các dữ liệu tương tự có sẵn từ một cuộc thi trên Kaggle cho huấn luyện tập train, dữ liệu thu thập tay cho tập development và test. Về mô hình có thể chọn hồi quy tuyến tính (logistic regression) với dữ liệu các pixel gốc hay chạy một mô hình đã huấn luyện sẵn (pre-trained network). Nên nhớ rằng, mục đích là chỉ cần chạy được, để khởi động cho vòng lặp.
Lời khuyên
Về tập test:
-
Vì mục đích là làm tốt trên tập test, vậy nên tập test cần phản ánh chính xác mục đích sản phẩm hay thương mại của dự án. Ví dụ khi bạn đang xây dựng 1 ứng dụng chẩn đoán tình trạng của da người qua ảnh selfie, bạn có thể train trên bất cứ dữ liệu nào, nhưng hãy đảm bảo dữ liệu test sẽ chứa những ảnh ánh sánh yếu, chất lượng kém như ảnh selfie.
-
Thay đổi tập test sẽ là thay đổi mục tiêu của nhóm, vậy nên nếu có thay đổi thì nên thay đổi sớm, và chỉ nên thay đổi khi có thay đổi về dự án, sản phẩm hay mục tiêu thương mại.
-
Tập test và development cần phải đủ lớn để dữ liệu không bị nhiễu, đủ chính xác cho mục đích đánh giá, so sánh các mô hình.
-
Cẩn thận với nhãn của dữ liệu, vì mỗi điểm dữ liệu sai sẽ tương ứng với một lỗi trong yêu cầu của sản phẩm (Product requirement)
-
Nên biết hiệu suất của người hoặc các hệ thống đã có trên tập test. Đó sẽ là một giới hạn trên “error rate” giúp bạn xác định hiệu suất tốt nhất có thể đạt được.
-
Đạt tới hiệu suất tương tự con người thường là mục tiêu dài hạn. Bởi cho đến cuối cùng, mục tiêu là tối ưu hiệu suất đến gần với chính con người nhất có thể.
Về tập development và train:
-
Tập development đại diện cho tập test, được sử dụng để điều chỉnh các siêu tham số (hyper-parameters). Như vậy, tập này cần có phân phối dữ liệu gần với tập test, nhưng không được giống hệt, cùng một nhóm người dùng, đầu vào. Có một cách hay được sử dụng đó là xáo dữ liệu lên rồi chia ra tập development và test (sao cho phân phối hai tập tương đương).
-
Nếu bạn nghĩ rằng dữ liệu sản phẩm có thể bị nhiễu, hãy xử lý nó ở tập train bằng các phép gia tăng (augmentation) và giảm chất lượng (degradation) dữ liệu. Không thế kì vọng mô hình chỉ học ảnh sắc nét mà lại đoán tốt trên ảnh mờ được.
Một khi đã có bản prototype, bạn có thể kiểm tra hiệu suất trên các tập dữ liệu. Đây cũng là bước cuối của vòng lặp. Đo đạc các biến động của khoảng cách giữa hiệu suất test và hiệu suất mong muốn đáp ứng tiêu chí hữu dụng của sản phẩm. Giờ là lúc bắt đầu vào chu trình của chúng mình.

Phân tích (Analyze)
Xác định “nút thắt cổ chai” (bottleneck)
Giai đoạn Phân tích cũng khá giống trong y học: Bạn được trang bị một số phương pháp chẩn đoán và mục tiêu là kết luận được cái gì đã giới hạn hiệu suất của mô hình. Tìm ra những vấn đề dễ dàng thấy được trước, hiểu được tác nhân nào có tác động lớn nhất tới vấn đề đó, bạn không cần phải cố gắng hiểu cũng như giải quyết tất cả các vấn đề, bởi rất nhiều vấn đề nhỏ sẽ thay đổi và thậm chí là biến mất khi mô hình được cải thiện.
Dưới đây là danh sách một số phương pháp cũng với chẩn đoán. Việc chọn ra phương pháp nào cũng là một nghệ thuật, sau khi áp dụng nhuần nhuyễn ML Engineering Loop bạn sẽ có được “trực giác” để biết mình nên thử cái nào.
Điểm bắt đầu của chúng mình có lẽ là để ý tới hiệu suất training, development và testing. Ở mỗi một chu trình, bạn nên thống kê các con số ở bước cuối cùng một cách tự động. Thông thường, training error development set error test set error
Phương pháp và chẩn đoán
Nếu training set error là nhân tố gây hạn chế hiệu suất, có thể do những vấn đề sau:
-
Thuật toán tối ưu không được hiệu chỉnh đúng. Nhìn vào learning curve để xem hàm loss có giảm không. Liệu mô hình có thể overfit một lượng dữ liệu nhỏ hơn không. Bạn có thể vẽ ra histogram của các phản hồi từ neuron để kiểm tra tính bão hòa (saturating)
-
Tập train có thể chứa dữ liệu đánh sai nhãn hoặc lỗi. Dò xét kĩ tập train trước khi đem vào mô hình để học.
-
Mô hình có thể quá bé. Ví dụ khi bạn dùng mô hình hồi quy tuyến tính cho bài toán phi tuyến tính, mô hình sẽ không tài nào học được. Khi đó ta nói mô hình high bias hay underfitting
Nếu development set error là nhân tố đó, các vấn dề khá tương tự:
-
Mô hình có thể quá lớn, quá phức tạp. Khi đó ta nói mô hình high variance hay overfitting
-
Dữ liệu chưa đủ để học hết các pattern
-
Phân phối của tập train không giống với tập development và test
-
Các siêu tham số chưa hiệu quả. Nếu bạn đang sử dụng một số phương pháp để tìm các siêu tham số này, nhiều khi chính phương pháp đó thật sự không hiệu quả.
-
Thành phần encode đầu vào cho mô hình thực sự không phù hợp với dữ liệu.
Và nếu test set error là nhân tố hạn chế, thì thường lý do là tập development quá nhỏ hay các bạn đã overfitting trên tập development qua nhiều thí nghiệm.
Với bất kỳ lý do nào kể trên, bạn đều có thể phân tích tập những mẫu dữ liệu mà mô hình đã học sai để hiểu bản chất vấn đề (Nhưng tuyệt đối không nên làm với tập test nhé để tránh “huấn luyện” trên những mẫu này).
-
Xác định các lỗi phổ biến bằng cách biểu diễn trực quan dữ liệu (visualizing the data). Nắm được tần suất của các loại lỗi trên dữ liệu. Trong bài toán phân loại (classification) confusion matrix sẽ giúp dễ dàng xác định được những class mà mô hình học tệ nhất. Sau đó bạn có thể tập trung vào giải quyết các loại lỗi đó.
-
Một số mẫu có thể bị đánh nhãn sai hoặc có nhiều hơn một nhãn.
-
Một vài mẫu có thể khó học hơn cái khác, hoặc bị thiếu thông thông tin. Hãy đánh mác lại cho các mẫu dữ liệu, có dữ liệu sẽ là “rất khó” và có dữ liệu lại “rất dễ”, kiểm soát được điều này sẽ giúp bạn tối ưu hơn trong việc giải quyết lỗi nào trước.
Một số chẩn đoán nêu trên sẽ có các khắc phục hiển nhiên, ví dụ như thiếu dữ liệu thì sẽ lấy thêm. Tuy nhiên, việc chia tách giai đoạn phân tích và chọn phương pháp sẽ giúp bạn hiểu rõ bản chất, phân tích các lỗi với một tâm thế thoải mái hơn.

Chọn phương pháp (Select Approach)
Tìm cách đơn giản nhất để giải quyết “nút thắt cổ chai”
Sau bước phân tích ở trên thì bạn đã hình dung được mình đang phải đối phó với những loại lỗi nào và tác nhân gây ra chúng rồi. Với một chẩn đoán, có thể sẽ có nhiều giải pháp khác nhau, bước tiếp theo chính là liệt kê và đánh giá độ ưu tiên cho chúng.
Tác giả khuyên rằng các Kĩ sư Học máy nên liệt kê ra càng nhiều ý tưởng càng tốt rồi bám theo những giải pháp đơn giản và nhanh. Nếu đã có sẵn một giải pháp có vẻ ổn thì dùng nó luôn. Có thể các phương pháp tinh vi, phức tạp sẽ cho kết quả tốt hơn, tuy nhiên qua thực tế tác giả thấy rằng sự cải thiện qua nhiều chu trình sẽ cho ra kết quả không tồi, hơn là chỉ chăm chăm sử dụng một giải pháp state-of-the-art, tốn khá nhiều thời gian. Giữa việc dán nhãn 1000 dữ liệu với nghiên cứu một phương pháp học không giám sát (unsupervised learning), mình nghĩ bạn nên thu thập và dán nhãn dữ liệu. Nếu như có một số heuristic đơn giản, bạn cũng nên thử chúng trước.
Lời khuyên
Phụ thuộc và chẩn đoán ma sẽ có một số giải pháp phổ biến như sau
Nếu bạn muốn hiệu chỉnh thuật toán để phù hợp dữ liệu hơn:
-
Thử điều chỉnh learning rate hay momentum. Bắt đầu với momentum nhỏ thôi (0.5).
-
Thử các chiến thuật khởi tạo khác nhau, hay bắt đầu với một mô hình pre-trained
-
Thử mô hình dễ hiệu chỉnh. Trong Deep learning, residual networks hay mạng sử dụng batch normalization có thể dễ hơn để huấn luyện
Nếu mô hình không thế phù hợp với dữ liệu train:
-
Sử dụng mô hình phức tạp hơn. Ví dụ khi dùng Cây quyết định (Decision tree), bạn có thể làm cho cây sâu hơn chẳng hạn.
-
Kiểm tra các mẫu trong tập train mà mô hình cho kết quả sai. Đầu tư thời gian vào làm sạch dữ liệu.
Nếu mô hình không khái quát được tập development:
-
Thêm dữ liệu train. Chú ý thêm dữ liệu mà giống với loại lỗi trên tập developemnt.
-
Tăng dữ liệu bằng cách sử dụng các kĩ thuật khác nhau, ví dụ như trong xử lý ảnh có thể dùng OpenCV để thêm hiệu ứng sương mù cho ảnh, làm ảnh mờ đi.
-
Thử các siêu tham số ở một khoảng rộng hơn để đảm bảo tìm được mô hình với hiệu suất tốt nhất.
-
Thử các biến thể khác của regularization (như weight decay, dropout, pruning)
-
Thử một loại mô hình khác. Trong Deep learning thì việc thử các mô hình rất thuận tiện vì các mạng neural thường được dựng thành các “building block” dễ dàng sử dụng. Nếu bạn sử dụng các mô hình truyền thống thì phần lớn công việc sẽ là tìm cách thay mô hình. Nhưng dù sao vẫn nên nhớ rằng, thử cái nào dễ trước nhé.

Thực thi (Implement)
Dựng cái gì bạn cần và làm nó thật nhanh
Vậy là bạn đã biết mình cần phải thử cái gì, bạn cũng đã làm cho nó đơn giản nhất có thể rồi. Giờ CHỈ cần bắt tay vào implement thôi. Mục tiêu của giai đoạn này là để nhanh chóng thử ý tưởng của bạn để có thể đo đạc, học từ đó và quay lại chu trình nhanh chóng. Do vậy, bạn chỉ nên làm những thử thực sự cần thiết. Tuy là nhanh nhưng bạn vẫn phải đảm bảo code của mình đúng nhé, hãy kiểm tra thường xuyên.
Lời khuyên
Khi thu thập và dán nhãn dữ liệu:
-
Thường xuyên kiểm tra dữ liệu. Kiểm tra dữ liệu thô, dữ liệu sau khi xử lý và nhãn. Bạn có thể sẽ tìm ra rất nhiều lỗi bằng việc kiểm tra thường xuyên dữ liệu của bạn đó.
-
Dán nhãn và làm sạch dữ liệu là điều hết sức bình thường. Nhiều người khá ngại việc thu thập và dán nhãn dữ liệu, đánh giá thấp bài toán với ít dữ liệu. Khi đã vào guồng thì bạn hoàn toàn có thể dán nhãn 20 cái ảnh trong một phút đấy. Bạn muốn dành một tiếng dán nhãn và một tiếng giải bài toàn phân loại với dữ liệu gồm 1200 ảnh hay là dành 3 tuần để có một mô hình học từ 5 mẫu ?
Khi bạn code một mô hình mới. Hãy bắt đầu từ những code tương tự. Có rất nhiều bài báo có mã nguồn mở trên mạng. Việc này sẽ giúp bạn tiết kiệm khối thời gian. Tác giả gợi ý các bước thực thi như sau:
-
Tìm một mã nguồn đã giải quyết vấn đề tương tự
-
Chạy lại mã nguồn với cùng tập dữ liệu và các siêu tham số.
-
Từ từ hiệu chỉnh mô hình và luồn dữ liệu sao cho phù hợp với những gì bạn cần.
-
Viết lại những phần cần thiết.
Viết đoạn mã kiểm thử gradients, các giá trị của tensor, dữ liệu đầu vào và nhãn xem đúng quy định chưa. Làm điều này ngay từ đầu sẽ giúp bạn kiểm tra lỗi bất cứ khi nào.

Đo đạc (Measure)
In ra các kết quả cũng như các số liệu để tiện theo dõi.
Nếu hiệu suất tăng, bạn đang đi đúng đường. Bạn có thể làm sạch các thành phần (component) mà bạn đang làm và đảm bảo rằng thí nghiệm có thể thực hiện lại được bởi cách thành viên khác trong đội.
Ngược lại, khi hiệu suất không tăng đáng kể thậm chí có thể tệ hơn, bạn phải quyết định nên tiếp tục hay bỏ ý tưởng hiện tại đi. Bỏ đi là khá dễ nếu như mỗi chu trình trong ML Loop có chi phí rẻ: bạn không tốn quá nhiều công để làm code “hoàn hảo”, và một lần thử nữa cũng không quá lâu.
Lời khuyên
-
Các số liệu đo hiệu suất bao gồm: độ chính xác, loss bên ML và những giá trị thương mại. Trong đó, những giá trị thương mại là thứ quan trọng nhất, bởi nó quyết định tính hữu dụng của thứ bạn đang làm. Nếu số liệu test (tối ưu bởi các thuật toán Học máy) của bạn không phù hợp với số liệu thương mại thì đây là lúc thích hợp để thay đổi các tiêu chí tối ưu hay tập test.
-
Đây cũng là lúc bản có thể tính toán các số liệu khác cần thiết dựa trên những số liệu đang có. Điều này sẽ giúp ích ở giai đoạn phân tích hoặc để quyết định xem có nên dừng ý tưởng hiện tại không.
-
Thêm một điều nhỏ nữa, bạn hãy tạo ra một cái Dashboard cho các số liệu để quan sát sau mỗi thí nghiệm. Cái này đặc biệt hữu ích trong làm việc nhóm nhé.
Tối ưu vòng lặp
ML Engieering Loop sẽ giúp bạn hình dung rõ về quá trình để có được một mô hình tốt hơn. Đây không phải là một hướng dẫn chi tiết, bạn sẽ phải phát triển khả năng của bản thân để có thể đưa ra sự lựa chọn hợp lý ở mỗi gia đoạn. Bạn cần phải làm quen nhanh chóng với các chu trình này, tìm cách cải tiến vòng lặp về cả chất lượng và tốc độ để có thể tối đa hóa các quá trình ở mỗi chu trình và nhiều chu trình trong thời gian ngắn.
Lời khuyên
-
Nếu giai đoan phân tích đang chậm, viết script để tóm tắt các kết quả, thu thập lỗi từ tập train, dev và biểu diễn một cách dễ nhìn. Cái “dashboard” này cực kỳ hữu ích cũng như tiết kiệm thời gian.
-
Nếu bạn vẫn đang mông lung không biết nêu thử cái gì, chỉ cần chọn đại một cái. Thử nhiều thứ một lúc sẽ khiến bạn chậm hơn. Bạn vẫn có thể thử một cái khác khi thí nghiệm đang chạy cơ mà.
-
Thu thập dữ liệu là một cách phổ biển để đạt được hiệu suất tốt hơn. Nếu việc lấy nhiều dữ liệu thật sự khó khăn, hãy tạo thêm công cụ để có thể thu thập, làm sạch và dán nhãn dữ liệu, bạn sẽ nó rất đáng để đầu tư đấy.
-
Hãy tham khảo ý kiến của các chuyên gia. Các chuyên gia trong lĩnh vực mà bạn đang tiếp cận thường có những cái nhìn cực kỳ hữu ích trong quá trình phân tích lỗi, trong khi đó các bài báo hay những người làm Học Máy kinh nghiệm sẽ cho bạn những hướng giải quyết khá sáng tạo, đáng để bạn thử đó.
-
Kĩ năng code là quan trọng, code đẹp có thể tránh được bugs. Tuy nhiên, trong quá trình thử bạn sẽ phải cắt xén code khá nhiều. Hãy thoải mãi với việc đó, bạn có thể “vệ sinh” code trước vòng lặp tiếp theo.
-
Nếu các thử nghiệm diễn ra quá lâu, bạn nên xem xét tối ưu code. Hãy nhờ đến sự giúp đỡ của một chuyên gia hệ thống để giúp bạn huấn luyện nhanh hơn. Nâng cấp GPU hay chạy nhiều thí nghiệm song song cũng là giải pháp thường thấy.
Kết luận
Như vậy, bài viết đã đưa ra một cách tiếp cận cho các dự án Học máy. Nếu như bạn cảm thấy mông lung và không biết bắt đầu từ đâu, hãy bắt đầu phân tích các lỗi, lên ý tưởng giải quyết, code chúng và xem nó hoạt động ra sao. Không ngừng tập trung vào chu trình trên một cách liên tục có thể đem đến những kết quả không ngờ trong cả nghiên cứu và ứng dụng đấy.
Ở dưới là link gốc của bài viết, trong quá trình dịch mình có thay đổi đôi chút cho phù hợp dựa vào kiến thức của bản thân. Cảm ơn bạn đã đọc bài viết !