
Introduction
3 types of existing articles about Image Captioning:
- Template-based image captioning
- Retrieval-based image captioning
- Novel image caption generation (Most deep learning based methods)
Deep-learning-based imge captioning methods:
- Visual space-based
- Multimodal space-based
- Supervised learning
- Other deep learning
- Dense captioning
- Whole scene-based
- Encoder-Decoder Architecture-based
- Compositional Architecture-based
- LSTM (Long Short-Term Memory) language model-based
- Others language model-based
- Attention-Based
- Semantic concept-based
- Stylized captions
- Novel object-based image captioning
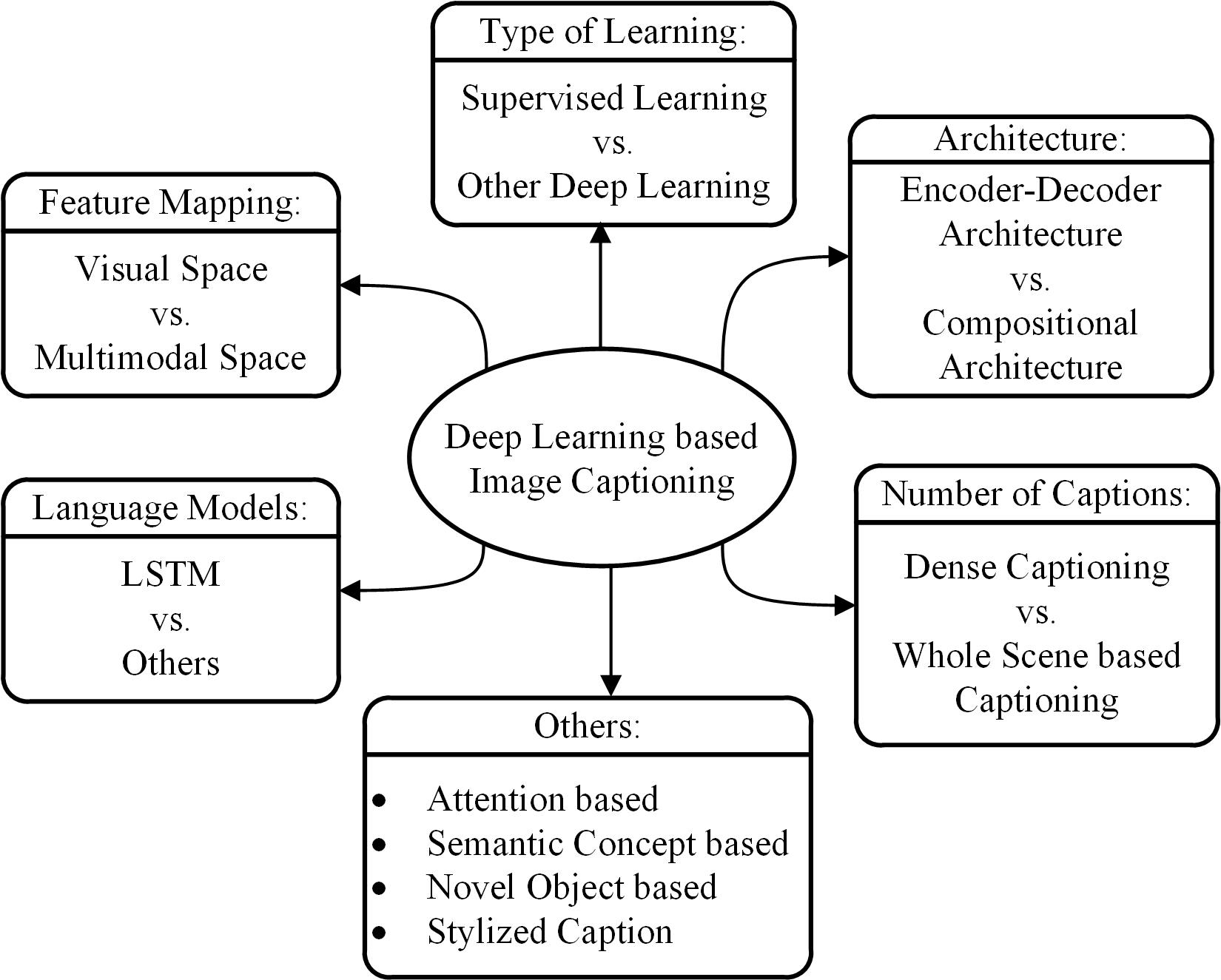
Image Captioning Methods
Deep Learning Based
Datasets và Evaluation Metrics
#Datasets
MS COCO Dataset: a very large dataset for image recognition, segmentation, and captioning; 300,000 images, 2 million instances, 80 object categories, and 5 captions per image.
Flickr30K Dataset: a dataset for automatic image description and grounded language understanding; 30k images collected from Flickr with 158k captions provided by human annotators.
Flickr8K Dataset: 8000 images collected from Flickr: 6000 train, 1000 test, 1000 dev images; each image has 5 reference captions annotated by humans.
Visual Genome Dataset: separate captions for multiple regions in an image; seven main parts: region descriptions, objects, attributes, relationships, region graphs, scene graphs, and question answer pairs; 108k images, each image contains an average of 35 objects, 26 attributes, and 21 pairwise relationships between objects.
Instagram Dataset: 1.1m posts, wide range of topics, long hashtag lists from 6.3k users.
IAPR TC-12 Dataset: 20k images, captions in multiple languages, multiple objects.
Stock3M Dataset: 3,217,654 images; diversity of content.
MIT-Adobe FiveK dataset: 5,000 images; people, nature, and man-made objects.
FlickrStyle10k Dataset: 10,000 Flickr images with stylized captions: 7,000 train - 2,000 dev - 1,000 test; romantic, humorous, and factual captions.
#Evaluation Metrics
BLEU: measure the quality of machine generated text, good only if the generated text is short
ROUGE: set of metrics that are used for measuring the quality of text summary
METEOR: another metric used to evaluate the machine translated language
CIDEr: automatic consensus metric for evaluating image descriptions
SPICE: new caption evaluation metric based on semantic concept
SPIDEr: combination of SPICE and CIDEr
BLEU, METEOR, ROUGE are not well correlated with human assessments of quality. SPICE and CIDEr have better correlation but they are hard to optimize.